
Big Data Solution Architect
Pure Non-relational
Tham khảo cho Data Analytics
Kiến trúc tham chiếu này không dựa trên các nguyên tắc mô hình quan hệ. Thường thì nó được xây dựng trên bộ lưu trữ NoSQL, Hadoop, Công cụ tìm kiếm và có hiệu quả cao để xử lý dữ liệu bán và phi cấu trúc.
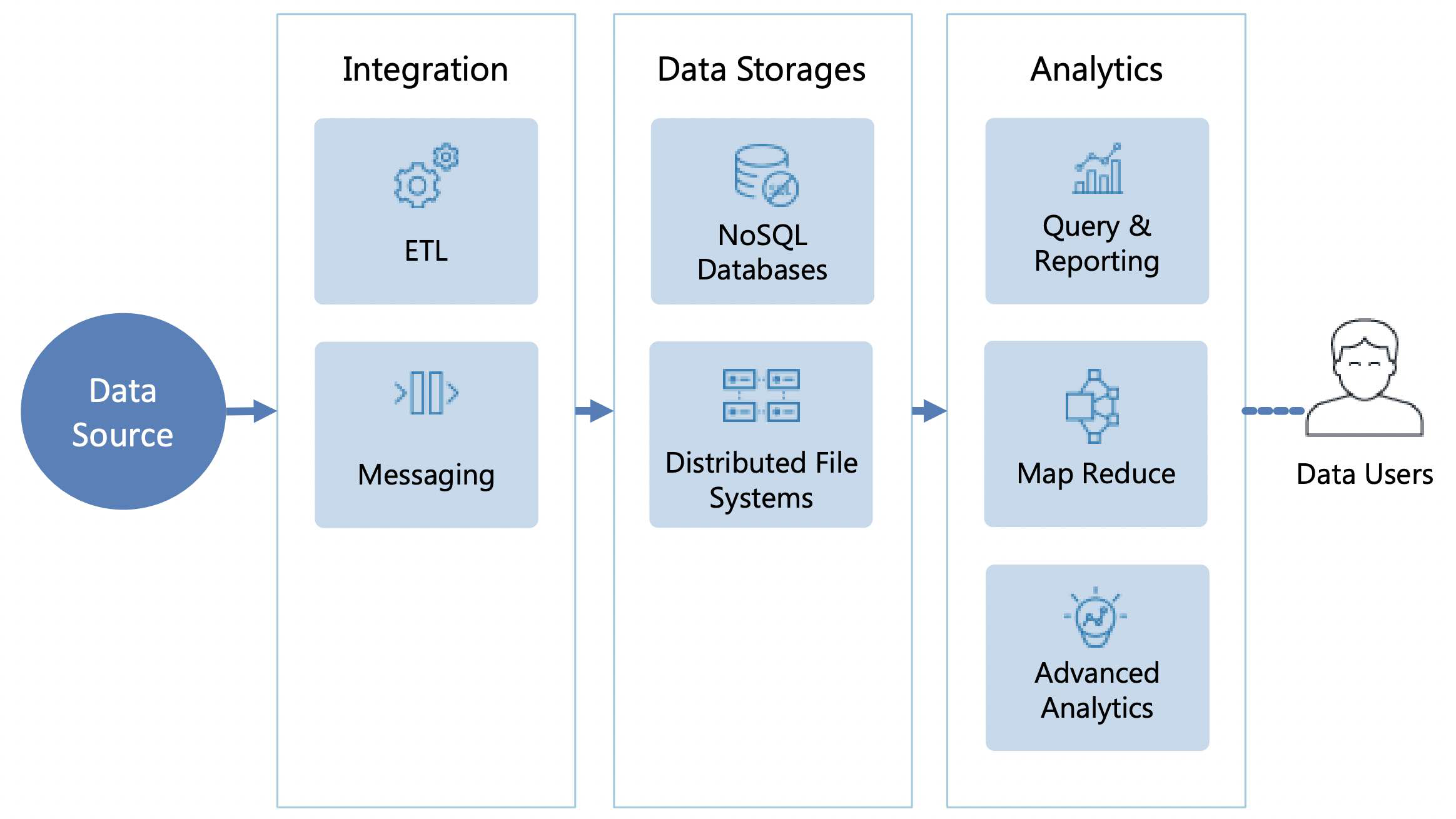
Các hệ quả:
★★ Ad-hoc analysis - hỗ trợ truy vấn thời gian thực đặc biệt khó hơn trong kiến trúc quan hệ
★★ ½ Phân tích thời gian thực - thời gian thực với xử lý từng lần
★★★ Xử lý dữ liệu không có cấu trúc - hỗ trợ dễ dàng lưu trữ và xử lý dữ liệu bán và phi cấu trúc
★★★ Khả năng mở rộng - có thể mở rộng quy mô giữ petabyte
★★★ Tiết kiệm chi phí - giảm thiểu chi phí do công nghệ nguồn mở
Ví dụ triển khai
Data Discovery, Data Lake, Operational Intelligence, Business Reporting
Extended Relational
Tham khảo cho Data Analytics
Mặc dù kiến trúc tham chiếu này hoàn toàn dựa trên các nguyên tắc mô hình quan hệ và DBMS dựa trên SQL, nhưng nó sử dụng chuyên sâu các kỹ thuật MPP và In-Memory để cải thiện khả năng mở rộng và khả năng mở rộng.
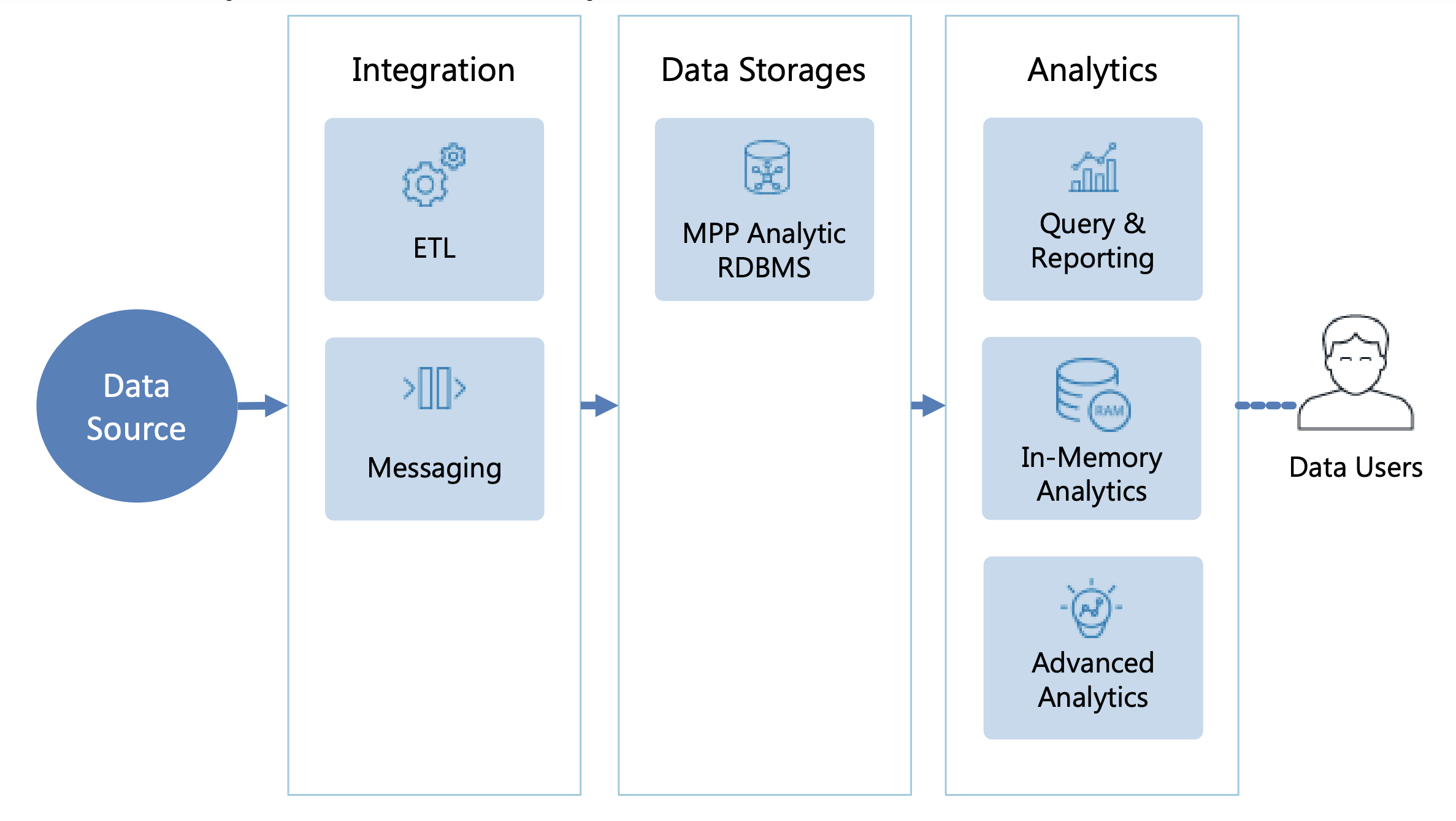
Các hệ quả:
★★★ Ad-hoc analysis - hỗ trợ các truy vấn đọc thời gian thực đặc biệt phức tạp
★★ Phân tích thời gian thực - thời gian gần thực với kỹ thuật phân lô vi mô
★★ Xử lý dữ liệu không có cấu trúc - hỗ trợ nhập và truy vấn dữ liệu có cấu trúc bán nguyệt như JSON / XML
★★ Khả năng mở rộng - có thể chạy terabyte với MPP và khả năng phân cụm
★ Tiết kiệm chi phí - Chi phí giấy phép MPP RDBMS khá đắt
Ví dụ triển khai
Business Reporting, Enterprise Data Warehousing, Data Discovery
Lambda Architecture (Hybrid)
Tham khảo cho Data Analytics
Kiến trúc tham chiếu này cho phép phân tích lịch sử và hoạt động theo thời gian thực trong cùng một giải pháp. Trong khi batch layer dựa trên các kỹ thuật không quan hệ (thường là Hadoop), thì speed Layer dựa trên kỹ thuật phân luồng để hỗ trợ các yêu cầu phân tích thời gian thực nghiêm ngặt.
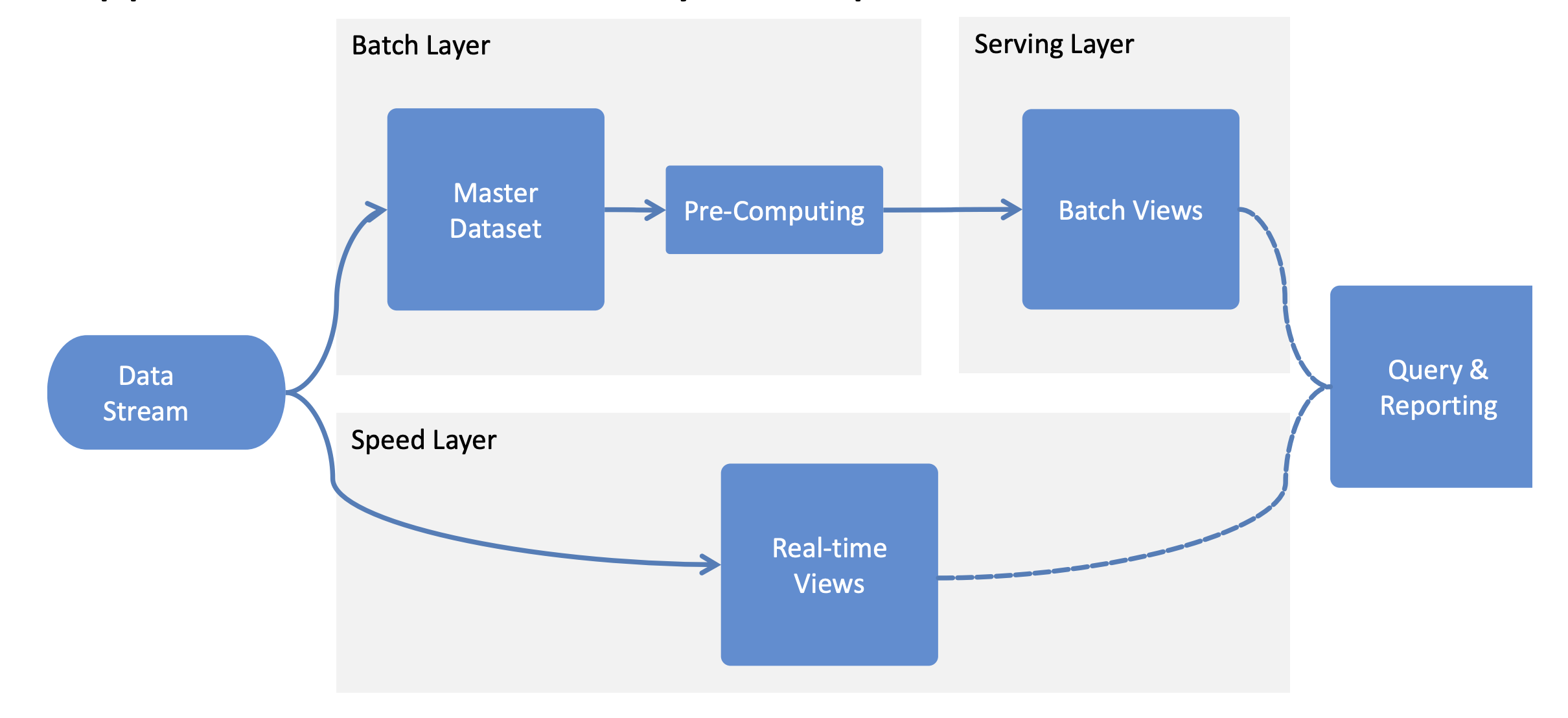
Các hệ quả:
★★ ½ Ad-hoc analysis - Hỗ trợ truy vấn thời gian thực đặc biệt khó hơn trong kiến trúc quan hệ
★★★ Phân tích thời gian thực - cách tiếp cận phát trực tuyến với độ trễ dữ liệu thấp
★★★ Xử lý dữ liệu không có cấu trúc - hỗ trợ xử lý dữ liệu bán và dữ liệu phi cấu trúc
★★★ Khả năng mở rộng - có thể mở rộng quy mô giữ petabyte
★★★ Tiết kiệm chi phí - giảm thiểu chi phí do công nghệ nguồn mở
Ví dụ triển khai
Real-time Intelligence, Data Discovery, Business Reporting
Data Refinery (Hybrid)
Tham khảo cho Data Analytics
Kiến trúc tham chiếu này là sự kết hợp của các kỹ thuật quan hệ và không quan hệ. Phần không quan hệ hoạt động như một ETL để tinh chỉnh dữ liệu bán và không có cấu trúc và tải nó đã được làm sạch vào kho dữ liệu quan hệ để phân tích thêm.

Các hệ quả:
★★★ Ad-hoc analysis - hỗ trợ các truy vấn đọc thời gian thực đặc biệt phức tạp
★ Phân tích thời gian thực - độ trễ dữ liệu cao do xử lý hàng loạt
★★★ Xử lý dữ liệu không có cấu trúc - hỗ trợ dễ dàng lưu trữ và xử lý dữ liệu bán và phi cấu trúc
★★ Khả năng mở rộng - có thể chạy terabyte với MPP và khả năng phân cụm
★ Tiết kiệm chi phí - chi phí giấy phép MPP RDBMS khá đắt
Ví dụ triển khai
Data Discovery, Business Reporting, Enterprise Data Warehousing
Data Collector
Family/Integration/Messaging
Mẫu này nhằm mục đích thu thập, tổng hợp và chuyển dữ liệu nhật ký để sử dụng sau này. Thông thường, các triển khai Data Collector cung cấp các plug-in sẵn có để tích hợp với các điểm đến và nguồn sự kiện phổ biến.
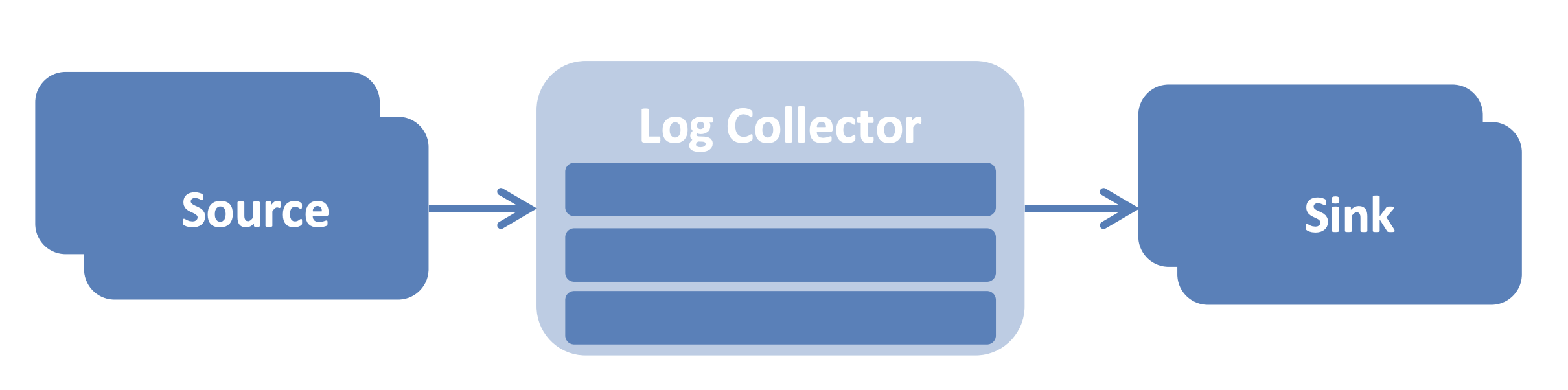
Các hệ quả:
★★ Hiệu suất - có thể xử lý lượng lớn dữ liệu trong thời gian thực
★★★ Khả năng tương thích - có thể được cắm với các nguồn và điểm đến sự kiện phổ biến
★★ Tính linh hoạt - áp đặt các giới hạn trong các tình huống sử dụng so với mẫu Nhà môi giới tin nhắn
Ví dụ triển khai
Apache Flume, Logstash, Fluentd, Scribe
Distributed Message Broker
Family/Integration/Messaging
Mô hình này là hậu duệ của Message Broker truyền thống hơn, nhưng cung cấp khả năng mở rộng cao bằng cách phân phối thông báo trên nhiều nút. Hầu hết các triển khai đều cung cấp các chế độ Pub / Sub và Peer-to-Peer.
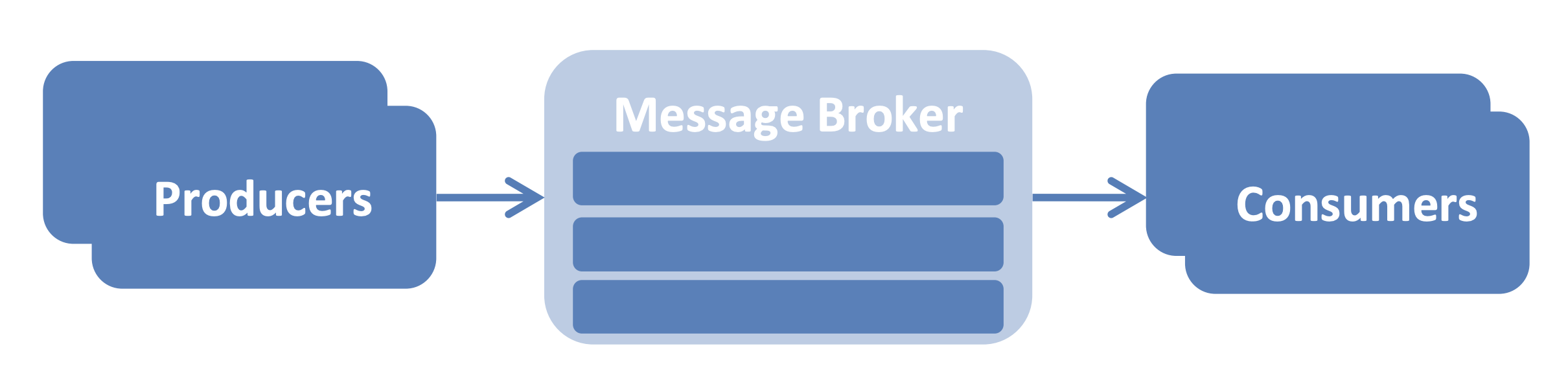
Các hệ quả:
★★★ Hiệu suất - có thể xử lý thông lượng cao với độ trễ thấp
★ Khả năng tương thích - trong hầu hết các trường hợp, yêu cầu viết mã tùy chỉnh để được cắm với nhà sản xuất sự kiện và người tiêu dùng
★★★ Tính linh hoạt - có thể được sử dụng cho nhiều mục đích - định tuyến, chuyển đổi, tổng hợp, pub-sub, v.v
Ví dụ triển khai
RabbitMQ, Apache Kafka, Apache ActiveMQ, Amazon SQS
Column-Family
Family/Data Storage/NoSQL Database
Mở rộng cơ sở dữ liệu Khóa-Giá trị bằng cách lưu trữ các bộ sưu tập không được xác định chính xác của một hoặc nhiều cặp khóa-giá trị khớp với một bản ghi. Có thể được trình bày dưới dạng mảng hai chiều, theo đó mỗi khóa có một hoặc nhiều cặp khóa-giá trị gắn liền với nó.
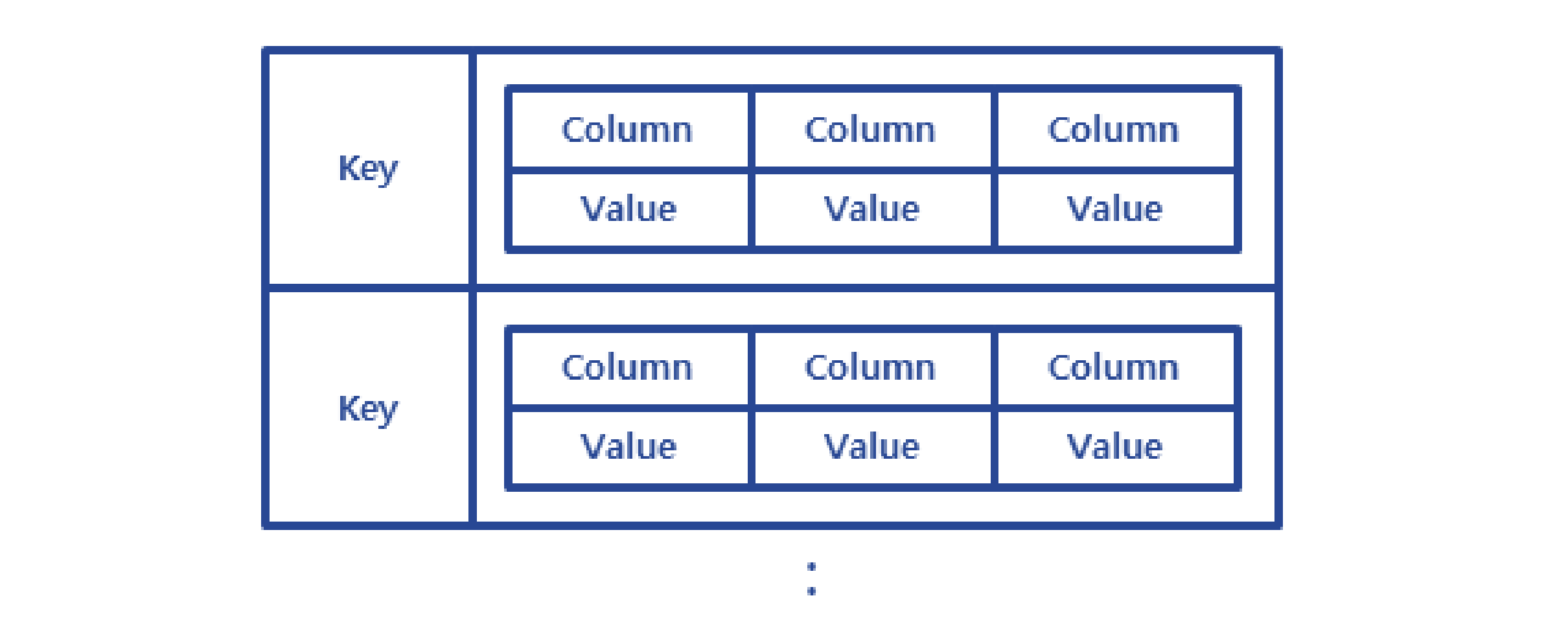
Các hệ quả:
★★★ Hiệu suất - cực kỳ nhanh do không có định nghĩa lược đồ, chức năng toàn vẹn quan hệ, giao dịch hoặc tham chiếu
★★★ Khả năng mở rộng - có thể được mở rộng tuyến tính bằng cách chia nhỏ dữ liệu trên các máy chủ bằng cách sử dụng giá trị băm được tính toán dựa trên khóa hàng
★★★ Tính khả dụng - tính khả dụng cao được cung cấp bởi hệ thống tệp phân nhóm và phân tán (ví dụ: HDFS)
★ Ad-hoc analysis - hỗ trợ lập chỉ mục thứ cấp, nhưng không có chức năng tổng hợp
Ví dụ triển khai
Cassandra, HBase
Column-Family
Family/Data Storage/NoSQL Database
Hoạt động tương tự như cơ sở dữ liệu Column-Family, nhưng cho phép lưu trữ các cấu trúc phức tạp và lồng sâu hơn nhiều (ví dụ: một tài liệu, trong một tài liệu, trong một tài liệu). Tài liệu vượt qua các ràng buộc của một hoặc hai cấp độ lồng khóa-giá trị của cơ sở dữ liệu Column-Family. Cấu trúc phức tạp và tùy ý có thể tạo thành một tài liệu, có thể được lưu trữ dưới dạng bản ghi.
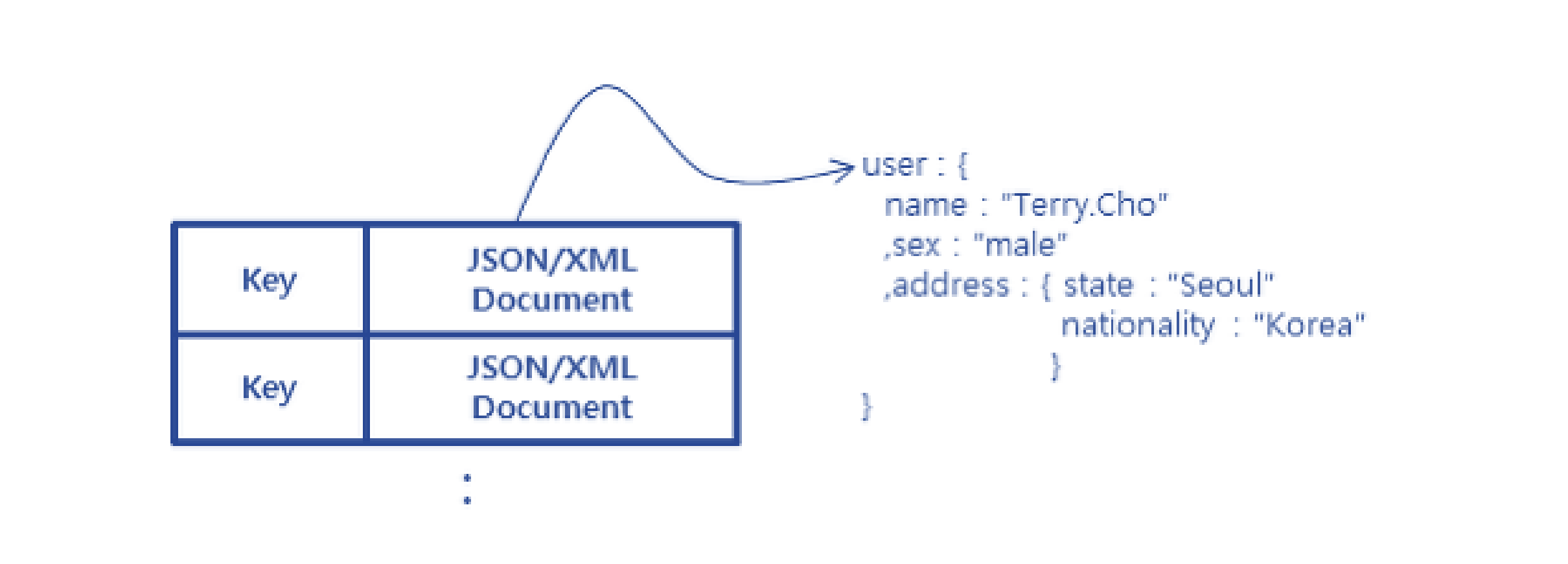
Các hệ quả:
★★ Hiệu suất - hiệu suất thay đổi đáng kể từ lần triển khai này sang lần triển khai tiếp theo, nhưng nhìn chung không nhanh bằng cơ sở dữ liệu Khóa-Giá trị
★★★ Khả năng mở rộng - hơn 100 tổ chức điều hành các cụm với hơn 100 nút. Một số cụm vượt quá 1.000 nút
★★★ Tính khả dụng - tính sẵn sàng cao được cung cấp bằng cách phân cụm và nhân rộng
★ ½ Ad-hoc analysis - tốt hơn một chút so với các họ NoSQL khác, nhưng vẫn không tốt bằng cơ sở dữ liệu quan hệ hoặc công cụ truy vấn tương tác
Ví dụ triển khai
MongoDB, CouchDB
Distributed File System
Family/Data Storage
Các hệ thống tệp phân tán hiện đại có khả năng chống lỗi cao và được thiết kế để chạy trên phần cứng giá rẻ. Các triển khai mã nguồn mở như HDFS (Hệ thống tệp phân tán Hadoop) và CFS (Hệ thống tệp Cassandra) cung cấp khả năng truy cập thông lượng cao vào dữ liệu ứng dụng và phù hợp với các ứng dụng xử lý tập dữ liệu lớn.

Các hệ quả:
★★ Hiệu suất - được thiết kế để truy cập đọc / ghi tuần tự nhanh, thực sự tốt cho xử lý hàng loạt (Map Reduce). Đối với việc đọc / ghi ngẫu nhiên được khuyến nghị sử dụng cơ sở dữ liệu NoSQL (ví dụ: HBase trên đầu HDFS
★★★ Khả năng mở rộng - có thể mở rộng quy mô và tuyến tính, số lượng nút về mặt lý thuyết là không giới hạn, các cụm sản xuất hiện có với tối đa 10.000 nút
★★★ Tính khả dụng - sao chép dữ liệu mặc định đến 3 nút, nhận biết giá đỡ và trung tâm dữ liệu, không có điểm lỗi duy nhất
Ví dụ triển khai
Hadoop Distributed File System(HDFS), Cassandra File System (CFS)
Interactive Query Engine
Family/Analytics/Search & Query
Bộ xử lý truy vấn phân tán nhằm mục đích chạy các truy vấn phân tích hàng loạt cũng như tương tác với các nguồn dữ liệu có kích thước lớn.

Các hệ quả:
★★ Hiệu suất - có thể truy vấn lượng lớn dữ liệu trong thời gian con người (2-30 giây), tuy nhiên vẫn không nhanh bằng kho dữ liệu quan hệ
★★ ½ Độ tin cậy - một số triển khai cung cấp hỗ trợ truy vấn lâu dài
★★★ Ad-hoc analysis - tốt nhất trong lớp, tương tự như các công cụ kho dữ liệu MPP quan hệ
Ví dụ triển khai
Hadoop Distributed File System(HDFS), Cassandra File System (CFS)
Distributed Search Engine
Family/Analytics/Search & Query
Giải pháp lập chỉ mục có thể mở rộng với tìm kiếm toàn văn, tương tác. Hầu hết các triển khai đều cung cấp API cho phép thực hiện các truy vấn phức tạp trên dữ liệu bán cấu trúc như nhật ký, trang web và tệp tài liệu.
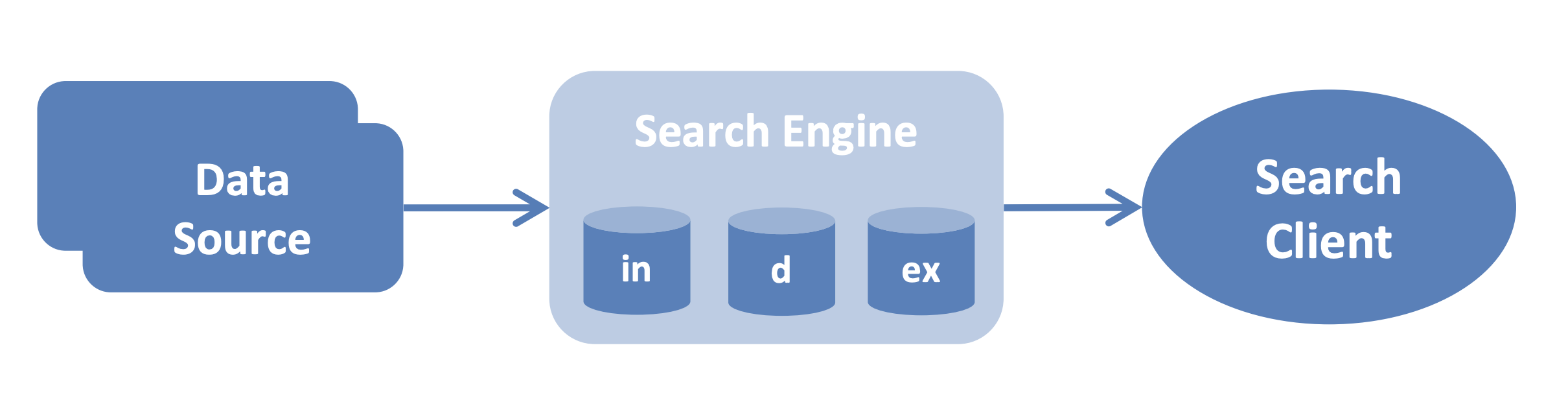
Các hệ quả:
★★ Ad-hoc analysis - ngôn ngữ truy vấn thường bao gồm tìm kiếm theo từng khía cạnh và không gian địa lý, các hàm thống kê và các phép nối đơn giản để truy vấn, phân tích và trực quan hóa dữ liệu
★★★ Khả năng mở rộng - có thể được mở rộng tuyến tính bằng cách cung cấp lập chỉ mục phân tán
★★★ Tính khả dụng - tính khả dụng cao được cung cấp bằng cách phân cụm và nhân rộng</br>
Ví dụ triển khai
Elasticsearch, Apache Solr, Splunk Indexer